I heard more and more often think like this: “If your website is to slow, you should use a CDN.” Great, CDN is THE solution for any kind of problems… or not. Depends what is our problem.
First of all let’s see what does CDN means. Content Delivery Network gives us the possibility to improve our web application performance by distributing our content in different geographical location that is closed to our client. This is a great solution when we have static content like images, videos or any kind of static content.
In this moment there are a lot of great solutions, from Azure CDN that are very easy to config and scalable to EdgeCast or Akamai.
But maybe our problem is not from there. What happens if users are in the same geographical region? Using a CDN may or not may improve our speed performance. The entire request will hit our servers. A bunny will tell us: “It’s not a problem dude, we live in the cloud nowadays, scale up your application on more instances”.
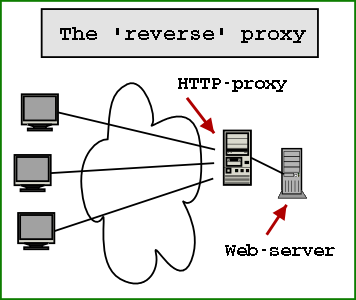
HTTP Caching Reverse Proxy is used for caching HTTP content. It is a proxy that stays between your servers and end uses. All the inbound traffic will hit your proxy and after that your web servers. This proxy will try to cache all the content (dynamical one) and will response to the client with the cached information (when is possible). What kind of content is cached can be directly controlled from images, to CSS or dynamic content.
 The reverse cache proxy is faster than our web servers, because all the assets can be served more rapidly. The content of the reverse cache proxy is not complicated and is not so mixed like our web servers. Because reserve cache proxies take a part of the calls that should hit our web servers, the web servers will respond faster. Web server will be able to server request that are more specific and will not spend precious resources delivering content.
The reverse cache proxy is faster than our web servers, because all the assets can be served more rapidly. The content of the reverse cache proxy is not complicated and is not so mixed like our web servers. Because reserve cache proxies take a part of the calls that should hit our web servers, the web servers will respond faster. Web server will be able to server request that are more specific and will not spend precious resources delivering content.
Let’s see why a reverse cache proxy is good:
Caching static content based on geographically location of the users (we eliminate the delay caused generated by user-location) is suitable for CDNs
If we want to reduce the trips to our web-serves, calls to our database and cache frequently content (dynamic, not only static) that reverse cache proxy can be our solution
In conclusion we saw when a CDN or a reverse cache proxy is good. We could say that CDN don’t eliminate the need of a reverse cache proxy. And a reverser cache proxy doesn’t eliminate the need of CDN. We can use both type of caching.
First of all let’s see what does CDN means. Content Delivery Network gives us the possibility to improve our web application performance by distributing our content in different geographical location that is closed to our client. This is a great solution when we have static content like images, videos or any kind of static content.
In this moment there are a lot of great solutions, from Azure CDN that are very easy to config and scalable to EdgeCast or Akamai.
But maybe our problem is not from there. What happens if users are in the same geographical region? Using a CDN may or not may improve our speed performance. The entire request will hit our servers. A bunny will tell us: “It’s not a problem dude, we live in the cloud nowadays, scale up your application on more instances”.
HTTP Caching Reverse Proxy is used for caching HTTP content. It is a proxy that stays between your servers and end uses. All the inbound traffic will hit your proxy and after that your web servers. This proxy will try to cache all the content (dynamical one) and will response to the client with the cached information (when is possible). What kind of content is cached can be directly controlled from images, to CSS or dynamic content.
{kind=link}
Let’s see why a reverse cache proxy is good:
- Any kind of content can be cached, from static one to dynamically one
- We can control the cache flush
- Our web servers will not be so loaded, reverse cache proxy will unload our servers
- The application don’t need to know about this caching mechanism and switching between with or without reverse caching mechanism can be without caching application
- Can be used out-of-the-box, it is implemented by another provider and we only need to use it
- Not connected with our application
- It is great for static content, that don’t change very often
- URLs need to be change a little to be able to use CDN
- A lot of servers located in different locations
- It is not connected with our application
- Recent CDNs can cache dynamic content also
Caching static content based on geographically location of the users (we eliminate the delay caused generated by user-location) is suitable for CDNs
If we want to reduce the trips to our web-serves, calls to our database and cache frequently content (dynamic, not only static) that reverse cache proxy can be our solution
In conclusion we saw when a CDN or a reverse cache proxy is good. We could say that CDN don’t eliminate the need of a reverse cache proxy. And a reverser cache proxy doesn’t eliminate the need of CDN. We can use both type of caching.
Comments
Post a Comment