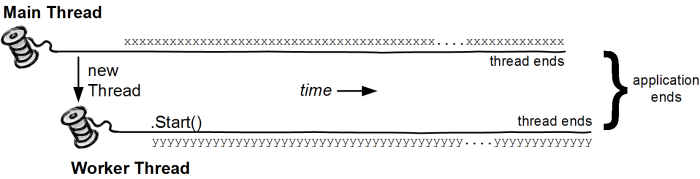
ThreadStatic is used when you have content that needs to be static per thread. For example we can have a field that needs to be static per thread and not per application. In the example below we can see that _message field is decorated with ThreadStatic attribute. Each thread will have a different instance of this field.
public class Foo
{
[ThreadStatic]
private static string _messageBuffer;
}
public class Foo
{
[ThreadStatic]
private static string _messageBuffer;
public void DoSomeAction(string input)
{
if ( _messageBuffer == null )
{
_messageBuffer = string.Empty;
}
_messageBuffer += input;
}
public void DoMoreAction(string input)
{
if ( _messageBuffer == null )
{
_messageBuffer = string.Empty;
}
_messageBuffer += " " + input;
}
...
}
public class Foo
{
[ThreadStatic]
private static string _messageBuffer = string.Empty;
public void DoSomeAction(string input)
{
_messageBuffer += input;
}
public void DoMoreAction(string input)
{
_messageBuffer += " " + input;
}
}
Now we understood why the check of null was made on each method. We know the cause, but the old solution was not so good at all.
A solution for our problem would be to create a wrapper property over our field. We need only the getter that can check if the field is initialize or not. In this way the null check will exist only in one location.
public class Foo
{
[ThreadStatic]
private static string _messageBuffer;
private static string MessageBuffer
{
get
{
if ( _messageBuffer == null )
{
_messageBuffer = string.Empty;
}
return _messageBuffer;
}
}
public void DoSomeAction(string input)
{
MessageBuffer += input;
}
public void DoMoreAction(string input)
{
MessageBuffer += " " + input;
}
}
If we have more fields that are thread static, we can add a Boolean that check if the thread static fields were initialized. In this way all the fields would be initialize from one shot.
public class Foo
{
[ThreadStatic]
private static string _messageBuffer;
[ThreadStatic]
private static int _messageCount;
[ThreadStatic]
private static StatusState _currentState;
[ThreadStatic]
private static bool _isInitialized = false;
private static InitializePerThreadContent()
{
_messageBuffer = string.Empty;
_messageCount = 1;
_currentState = StatusState.Empty;
_isInitialized = true;
}
private static string MessageBuffer
{
get
{
if ( !_isInitialized )
{
InitializePerThreadContent();
}
return _messageBuffer;
}
}
private static string MessageCount
{
get
{
if ( !_isInitialized )
{
InitializePerThreadContent();
}
return _messageCount;
}
}
private static string CurrentState
{
get
{
if ( !_isInitialized )
{
InitializePerThreadContent();
}
return _currentState;
}
}
...
}
An alternative for your solution would be the use of the System.Threading.ThreadLocal class, present inside .NET framework since version 4.0.
ReplyDelete