Providing learning and training cloud environments where
engineers can play around it’s not so cheap as you might think. One of the most
expensive resources are the computation ones likes VMs that are used not only
to play with the cloud itself but also to host training resources like a specific
CMS.
In general, the training environments are not required to
run 24/7. In most of the cases they are used only during the working hours 8/5.
Additional to this it is not required for them to run the full working hours.
They can be spin-up only when there are persons that want to use them,
otherwise, there is no need to run them.
By reducing the running of VMs from 24/7 to 8/5 you
automatically save around 60% of VMs cost during the year. For example, for a
training environment that initially was estimated to around $4000/year, the
cost was reduced to $2500 by only reducing the running time from 24/7 to 8/5.
Startup/Shutdown automatically
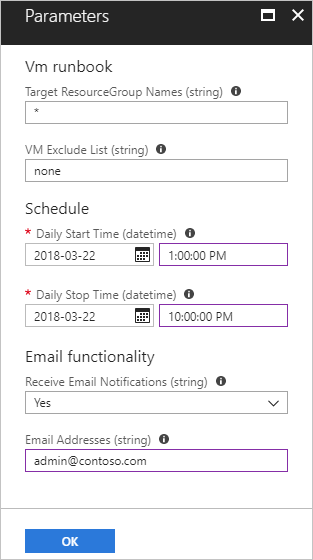
Microsoft Azure - Runbooks can be used inside Azure to do
automation. You can define a runbook that starts a VMs under a resource group
automatically at a specific hour and shut down in the evening. If you can find
more check the official Azure documentation - https://docs.microsoft.com/en-us/azure/automation/automation-solution-vm-management
AWS – The official solution provides by Amazon it is based
on AWS Functions, Amazon DynamoDB and CloudWatch. Inside AWS DynamoDB the schedule
is stored and the action of startup and shut down of VMs is done by Azure
Function that it is triggered by AWS CloudWatch. The CloudFormation template to
implement this solution can be found here - https://aws.amazon.com/solutions/instance-scheduler/
Start Manually / Shutdown automatically

In the above solutions, the biggest problem is that your VMs
are not used all the time. Because of this, you might have days when the VMs are
available, but nobody is using them. For these situations, you can define using
the automation solution presented above only the shutdown implementation. The start
of the VMs is done manually by each user when he needs the resources.
You might want to have some VMs start automatically in the
morning and the rest of them would start only when needed.
Dev/Test Labs Environments
When things are becoming more complicated, and you need to
do define access policies, have higher control of resources and want kind of
actions can be done by each user you can start to use solutions like Azure
DevTest Labs that enables developers to
manage their VMs by themselves. At the same time at company level, you can
define policies related to what kind of VMs can be spin-up, the no. of them,
the time when all resources are shut down in the afternoon and many more.
Conclusion
I prefer the option no. 1 or 2 where you have automatical
systems that can spin-up or shut-down the computation resources. There is
enough flexibility to let the engineers defining their schedule. At the same
time, you have the policy layer on top of resources that enable you to control the
costs.
When you are in these situations take into account the following
aspects:
- - Maximum no. of VMs that can be created
- - Who has the rights to create new VMs
- - Who has the rights to start a VMs
- - Who can change the tier side of the VMs
- - Is a shut-down automatic mechanism in place?
- - Who can configure the shut-down mechanism?
Comments
Post a Comment