Let’s talk about different branching strategies that can be used when you use Git. Let’s assume that you are working on a project where based on what clients need (and pay) you shall be able to provide a specific list of features. Each client can decide what feature he wants to buy and use.
The code is hosted inside Azure DevOps where you have a private Git repository. The solution is designed in such a way that you have a CORE layer, that it is common for all features. Because of the project complexity and how the solution is designed you cannot isolate each feature in a separate location. It means that the implementation of each feature can be found across the projects, in 2-3 different locations.
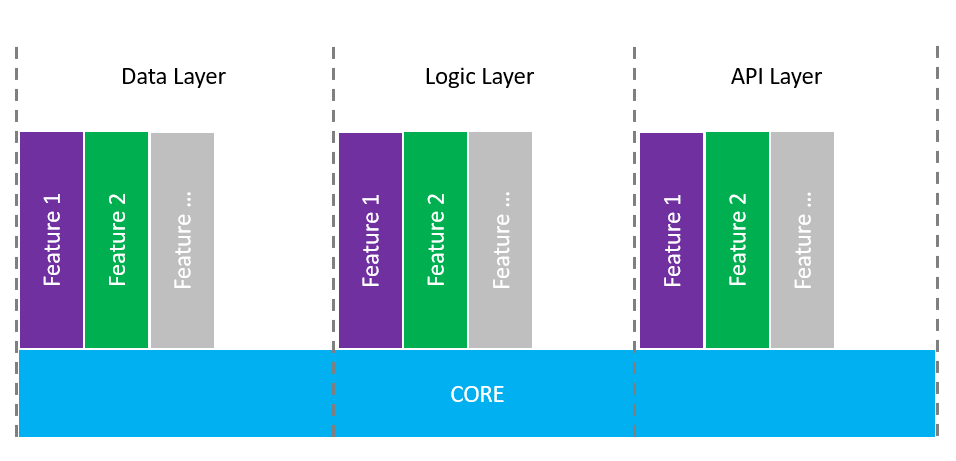
A good approach that you can have is to create a branch for your CORE layer. Once this layer is stable for each feature, you can create a new branch from the CORE layer.
The most significant advantage of this approach is the ability to merge different features at the moment when you need to build a specific solution for one of your clients. You can decide what the features that you want to include are.
Additional to this, on each feature branch, you can work without affecting the other features. Bugfix-ing and feature enhancements are done in an isolated environment, dedicated to that specific feature.
The complexity of the solution remains low by having a decomposition approach on top of Git branches.

The above approach is smart and keeps things simple, especially at a technical level. You don’t mix features between each other, and you can have at any time a clean solution with only the things that you need.
There is a moment in time when this approach adds extra complexity and generate an extra effort from a technical perspective. That moment is when the CORE is changed.
Any activity that is changing the CORE, from refactoring to a small change in the design will be required to push the change on each feature branch. When for example you do refactoring you might need also integrate the change to each feature, by updating how each feature is implemented or works.
Even if you would have all the features in one branch, you would still need to do the fix; there is no doubt. The nice thing with this approach is that you can still use the previous version of the CORE combined with old versions of the features until you integrate the changes in all features. This is general for other approaches also, because you can create a branch each time when you have a stable version (or use tagging).
An interesting problem appears in the moment when you need to do a refactoring for example at the CORE. Because you have multiple branches, the technical team will have a hard time to estimate the real effort of the refactoring and the complexity level. They need to take each feature branch separately and analyze the effort.
At this moment I think that the extra complexity that adds this approach is useful when inside your product you have a small number of features or variants that you want to separate. If you know from the beginning that you'll end up with 20 or 25 features this approach might not be the best one.
What should you do?
There is no solution that feets all cases. There are some things that I would recommend to take into account:
- Understand the feature complexity and no. of features
- Analyze the current approach and identify if each feature can be extracted in an isolated location (dedicated project)
- Use a Dependency Injection mechanism that allows you to add at runtime features
- Build each feature separately, isolated from the CORE
- Decide if you deploy at the client all featured and you control from the license one features are active OR you deploy only the features included in the license
- Consider using a package repository like Nexus and define clearly what a package contains and a packaging strategy
- Analyze the solution complexity during the full life cycle of the application take this into consideration when you decide the feature strategy
Remember that there is no solution that fits all. Try to keep things as simple as possible for your current needs and at the same time you need a solution that is open to change in the future.
Comments
Post a Comment