Let's discover together another approach to collect and transform information that is send by devices.
Context
 In the world of smart devices, devices are more and more chatty. Let’s assume that we have a smart device that needs to sends every 30 seconds a Location Heartbeat that contains <device ID, GPS location, time sample>. Worldwide we have 1.000.000 devices that sends this information to our backend.
In the world of smart devices, devices are more and more chatty. Let’s assume that we have a smart device that needs to sends every 30 seconds a Location Heartbeat that contains <device ID, GPS location, time sample>. Worldwide we have 1.000.000 devices that sends this information to our backend.
At global level, backend runs on 4 different Azure Regions, with an equal distribution of devices. This means that on each instance of our backend there will be 250.000 devices that sends heartbeats with their locations.
From a load perspective, it means that on each Azure Region there are around 8.300 heartbeats requests every second. 8K messages per second might be or not an acceptable load, it depends on what actions we need to do for each request.
Requirements
From the end user there are two clear requirements that needs to be full fit:
The first requirement is pretty relax. From implementation point of view we need to persist all the location heartbeats in a repository. The repository can be a file base repository.
The second requirement is a little more complex. It requires to have available all the time the last location of the device.
Classical solution
The standard solution for this situation is to have an event messaging system that aggregates all the location heartbeats from devices. On Azure, we can use with success Azure Event Hub, that is able to ingest high throughput.
Behind it we need a computation unit that can scale up easily. The main scope of this unit shall be to process each location heartbeat by dumping the information in a storage for audit and update the last location of the device.
For processing we can use with success Worker Roles or Azure Service Fabric. In both situations, you shall expect that the processing action will take around 0.4-0.5s (dumping data and update the last location). This means that you will need at least 16 instances of Worker Roles that will do this job.
The audit of the device location can be dumped easily in blobs. If you don’t want to do this by hand you can use Azure Event Hubs Archive (https://azure.microsoft.com/en-us/blog/azure-event-hubs-archive-in-public-preview/). This new feature offered by Azure, can do this job for you, dumping all the events directly in blobs. This solution is applicable as long as you don’t need to do a transformation of messages.
For storing the last location, there are many options. The faster one is to have in memory cache like NCache and update the last location. The downside of this approach is that you will need to access this information and an API shall be available or at a specific time interval a dump to Azure Table or SQL shall be done.
You might ask why I not propose Azure Redis Cache or another cache service. When you do a lot of writes, a cache system doesn’t behave as you expect. In the past we had problems with such solution where the read and write latency has 2-5s because of heavy writes (yes, there were a lot of write operations).
A better solution is with Azure Tables. Each raw stores the last location of a device. Each time when a new location is received we update the location information. You can replace Azure Table with SQL if the reports that you need to do are complex or you need to be able to generate the reports on the fly (even for this situations, Azure Table can be a good friend).

Cost
Even if we try to optimize the code, writing the last location of devices is expensive. You need to identify the device, get the table, write the content. This means that even if you reduce the time from 0.4-0.5s to 0.2-0.3 it will still be expensive.
To be able to consume and process 8.300 location heartbeats per second it will still be costly. Let’s assume that you manage to process 500 on a Worker Role. This would translate in at least 17-18 instances of worker roles.
Identify the bottleneck
We need to try to see how we can use Azure Services that are available now on the market in our advantages. We need to try to reduce our custom code. For long term this means that will have lowest cost for maintenance and support – number of bugs will be also lower.
Our assumption is that we cannot use Azure Event Hub Archive because there is some transformation that needs to be done to store in the agreed audit format.
First thing that we shall do is to separate these two requirements in different modules. The first module would create the audit data and the other one will store the last location of the device.
Remarks: Whatever you do, you shall use Event Processor Host to consume messages from Event Hub. This will ensure you that you will have:
If we run separately this two modules, we observe that processing the location heartbeats only for audit is extremely fast. On a single worker role, we are able to process 4000-5000 location heartbeats per second. In contrasts with the action of updating the last device location that is an expensive action.
The problem is not coming from Azure Table, where latency is low. The difference is that for audit you only transform the message and dump them, where strategies like buffering can be used to optimize this kind of actions. Whatever we do, we cannot process more than max 600 location heartbeats per second on each computation instance.
Let’s be inventive
We observed that creating the audit data is a low consuming action. Storing the last location of device is expensive. If we are looking again at last device location, we realize that this action could be done directly by device.
Why not making the device to update directly his own Azure Table Row with his last known location? In this way we don’t have to process the data and update the last location using backend resources.
From access perspective, Azure Table Shared Access Signature (SAS) allows us to offer granularity access at partition and row key level. Each device can have access only to his own raw from table.

In the end each device ends up doing a request to Azure Table to update the last known location and another requests to Azure Event Hub to push the location heartbeat for audit. On the backend the load is decreased drastically. We need only the Worker Roles instances that create our audit data. In Azure Tables we will have the last location of each device that is available for reporting or other type of actions.
At device level things change a little bit. Now, for each location heartbeat, a device needs to do two different requests. This means that the device will consume more bandwidth, a little bit more CPU and more bandwidth. This approach is valid for devices that have a good internet connection (cheap) and no CPU strict limitations.
In this way we move the load from one place to another, increasing the noise on the internet (smile).
Another approach is to have a dedicated Azure Table for each device, where devices add new rows all the time. We will not explore this solution, that might be interesting as long as we don't need complex reports.
Conclusion
To solve a business problem there are all the time multiple solutions and approaches. There are times, when is a good approach to make a step back and see how we can use services that are available on the market to solve different problems.
Making direct calls to different services might be a better solution, but never forget about the cost of making that request at device level.
Context
 In the world of smart devices, devices are more and more chatty. Let’s assume that we have a smart device that needs to sends every 30 seconds a Location Heartbeat that contains <device ID, GPS location, time sample>. Worldwide we have 1.000.000 devices that sends this information to our backend.
In the world of smart devices, devices are more and more chatty. Let’s assume that we have a smart device that needs to sends every 30 seconds a Location Heartbeat that contains <device ID, GPS location, time sample>. Worldwide we have 1.000.000 devices that sends this information to our backend.At global level, backend runs on 4 different Azure Regions, with an equal distribution of devices. This means that on each instance of our backend there will be 250.000 devices that sends heartbeats with their locations.
From a load perspective, it means that on each Azure Region there are around 8.300 heartbeats requests every second. 8K messages per second might be or not an acceptable load, it depends on what actions we need to do for each request.
Requirements
From the end user there are two clear requirements that needs to be full fit:
- Full history of device locations is stored for audit
- Last device location needs to be accessible all the time
The first requirement is pretty relax. From implementation point of view we need to persist all the location heartbeats in a repository. The repository can be a file base repository.
The second requirement is a little more complex. It requires to have available all the time the last location of the device.
Classical solution
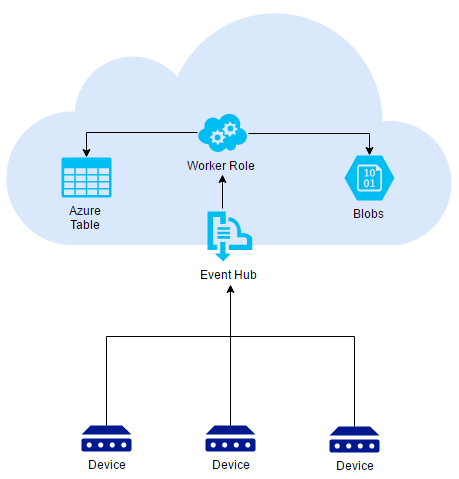
The standard solution for this situation is to have an event messaging system that aggregates all the location heartbeats from devices. On Azure, we can use with success Azure Event Hub, that is able to ingest high throughput.
Behind it we need a computation unit that can scale up easily. The main scope of this unit shall be to process each location heartbeat by dumping the information in a storage for audit and update the last location of the device.
For processing we can use with success Worker Roles or Azure Service Fabric. In both situations, you shall expect that the processing action will take around 0.4-0.5s (dumping data and update the last location). This means that you will need at least 16 instances of Worker Roles that will do this job.
The audit of the device location can be dumped easily in blobs. If you don’t want to do this by hand you can use Azure Event Hubs Archive (https://azure.microsoft.com/en-us/blog/azure-event-hubs-archive-in-public-preview/). This new feature offered by Azure, can do this job for you, dumping all the events directly in blobs. This solution is applicable as long as you don’t need to do a transformation of messages.
For storing the last location, there are many options. The faster one is to have in memory cache like NCache and update the last location. The downside of this approach is that you will need to access this information and an API shall be available or at a specific time interval a dump to Azure Table or SQL shall be done.
You might ask why I not propose Azure Redis Cache or another cache service. When you do a lot of writes, a cache system doesn’t behave as you expect. In the past we had problems with such solution where the read and write latency has 2-5s because of heavy writes (yes, there were a lot of write operations).
A better solution is with Azure Tables. Each raw stores the last location of a device. Each time when a new location is received we update the location information. You can replace Azure Table with SQL if the reports that you need to do are complex or you need to be able to generate the reports on the fly (even for this situations, Azure Table can be a good friend).
Cost
Even if we try to optimize the code, writing the last location of devices is expensive. You need to identify the device, get the table, write the content. This means that even if you reduce the time from 0.4-0.5s to 0.2-0.3 it will still be expensive.
To be able to consume and process 8.300 location heartbeats per second it will still be costly. Let’s assume that you manage to process 500 on a Worker Role. This would translate in at least 17-18 instances of worker roles.
Identify the bottleneck
We need to try to see how we can use Azure Services that are available now on the market in our advantages. We need to try to reduce our custom code. For long term this means that will have lowest cost for maintenance and support – number of bugs will be also lower.
Our assumption is that we cannot use Azure Event Hub Archive because there is some transformation that needs to be done to store in the agreed audit format.
First thing that we shall do is to separate these two requirements in different modules. The first module would create the audit data and the other one will store the last location of the device.
Remarks: Whatever you do, you shall use Event Processor Host to consume messages from Event Hub. This will ensure you that you will have:
- High throughout
- Scalable solution
- Failover between nodes
If we run separately this two modules, we observe that processing the location heartbeats only for audit is extremely fast. On a single worker role, we are able to process 4000-5000 location heartbeats per second. In contrasts with the action of updating the last device location that is an expensive action.
The problem is not coming from Azure Table, where latency is low. The difference is that for audit you only transform the message and dump them, where strategies like buffering can be used to optimize this kind of actions. Whatever we do, we cannot process more than max 600 location heartbeats per second on each computation instance.
Let’s be inventive
We observed that creating the audit data is a low consuming action. Storing the last location of device is expensive. If we are looking again at last device location, we realize that this action could be done directly by device.
Why not making the device to update directly his own Azure Table Row with his last known location? In this way we don’t have to process the data and update the last location using backend resources.
From access perspective, Azure Table Shared Access Signature (SAS) allows us to offer granularity access at partition and row key level. Each device can have access only to his own raw from table.

In the end each device ends up doing a request to Azure Table to update the last known location and another requests to Azure Event Hub to push the location heartbeat for audit. On the backend the load is decreased drastically. We need only the Worker Roles instances that create our audit data. In Azure Tables we will have the last location of each device that is available for reporting or other type of actions.
At device level things change a little bit. Now, for each location heartbeat, a device needs to do two different requests. This means that the device will consume more bandwidth, a little bit more CPU and more bandwidth. This approach is valid for devices that have a good internet connection (cheap) and no CPU strict limitations.
In this way we move the load from one place to another, increasing the noise on the internet (smile).
Another approach is to have a dedicated Azure Table for each device, where devices add new rows all the time. We will not explore this solution, that might be interesting as long as we don't need complex reports.
Conclusion
To solve a business problem there are all the time multiple solutions and approaches. There are times, when is a good approach to make a step back and see how we can use services that are available on the market to solve different problems.
Making direct calls to different services might be a better solution, but never forget about the cost of making that request at device level.
Comments
Post a Comment